@@ -59,9 +59,9 @@ When starting each replica, `text-generation-launcher` downloads the model to th
usually takes under a minute, but larger models may take longer. Repeated downloads can significantly affect
auto-scaling efficiency.
-Great news: RunPod supports network volumes, which we can use for caching models across multiple replicas.
+Great news: Runpod supports network volumes, which we can use for caching models across multiple replicas.
-With `dstack`, you can create a RunPod volume using the following configuration:
+With `dstack`, you can create a Runpod volume using the following configuration:
@@ -130,7 +130,7 @@ resources:
In this case, `dstack` attaches the specified volume to each new replica. This ensures the model is downloaded only
once, reducing cold start time in proportion to the model size.
-A notable feature of RunPod is that volumes can be attached to multiple containers simultaneously. This capability is
+A notable feature of Runpod is that volumes can be attached to multiple containers simultaneously. This capability is
particularly useful for auto-scalable services or distributed tasks.
Using [volumes](../../docs/concepts/volumes.md) not only optimizes inference cold start times but also enhances the
diff --git a/docs/docs/concepts/backends.md b/docs/docs/concepts/backends.md
index bf731823f..620d5723c 100644
--- a/docs/docs/concepts/backends.md
+++ b/docs/docs/concepts/backends.md
@@ -1132,9 +1132,9 @@ projects:
> To learn more, see the [Lambda](../../examples/clusters/lambda/#kubernetes) and [Crusoe](../../examples/clusters/crusoe/#kubernetes) examples.
-### RunPod
+### Runpod
-Log into your [RunPod](https://www.runpod.io/console/) console, click Settings in the sidebar, expand the `API Keys` section, and click
+Log into your [Runpod](https://www.runpod.io/console/) console, click Settings in the sidebar, expand the `API Keys` section, and click
the button to create a Read & Write key.
Then proceed to configuring the backend.
diff --git a/docs/docs/concepts/snippets/manage-fleets.ext b/docs/docs/concepts/snippets/manage-fleets.ext
index c9835fc67..b30b4126a 100644
--- a/docs/docs/concepts/snippets/manage-fleets.ext
+++ b/docs/docs/concepts/snippets/manage-fleets.ext
@@ -7,4 +7,4 @@ If the run reuses an existing fleet instance, only the fleet's
If an instance remains `idle`, it is automatically terminated after `idle_duration`.
-> Not applied for container-based backends (Kubernetes, Vast.ai, RunPod).
+> Not applied for container-based backends (Kubernetes, Vast.ai, Runpod).
diff --git a/docs/docs/guides/migration/slurm.md b/docs/docs/guides/migration/slurm.md
index d00649739..102077884 100644
--- a/docs/docs/guides/migration/slurm.md
+++ b/docs/docs/guides/migration/slurm.md
@@ -908,7 +908,7 @@ resources:
#### Network volumes
-Network volumes are persistent cloud storage (AWS EBS, GCP persistent disks, RunPod volumes).
+Network volumes are persistent cloud storage (AWS EBS, GCP persistent disks, Runpod volumes).
Single-node task:
@@ -936,7 +936,7 @@ resources:
-Network volumes cannot be used with distributed tasks (no multi-attach support), except where multi-attach is supported (RunPod) or via volume interpolation.
+Network volumes cannot be used with distributed tasks (no multi-attach support), except where multi-attach is supported (Runpod) or via volume interpolation.
For distributed tasks, use interpolation to attach different volumes to each node.
diff --git a/docs/docs/guides/protips.md b/docs/docs/guides/protips.md
index 4aa5df93f..dcf3fe196 100644
--- a/docs/docs/guides/protips.md
+++ b/docs/docs/guides/protips.md
@@ -218,7 +218,7 @@ If the run reuses an existing fleet instance, only the fleet's
If an instance remains `idle`, it is automatically terminated after `idle_duration`.
-> Not applied for container-based backends (Kubernetes, Vast.ai, RunPod).
+> Not applied for container-based backends (Kubernetes, Vast.ai, Runpod).
## Volumes
diff --git a/examples/accelerators/amd/README.md b/examples/accelerators/amd/README.md
index a660acddc..9dfe36441 100644
--- a/examples/accelerators/amd/README.md
+++ b/examples/accelerators/amd/README.md
@@ -55,7 +55,7 @@ Llama 3.1 70B in FP16 using [TGI](https://huggingface.co/docs/text-generation-in
type: service
name: llama31-service-vllm-amd
- # Using RunPod's ROCm Docker image
+ # Using Runpod's ROCm Docker image
image: runpod/pytorch:2.4.0-py3.10-rocm6.1.0-ubuntu22.04
# Required environment variables
env:
@@ -125,7 +125,7 @@ To request multiple GPUs, specify the quantity after the GPU name, separated by
type: task
name: trl-amd-llama31-train
- # Using RunPod's ROCm Docker image
+ # Using Runpod's ROCm Docker image
image: runpod/pytorch:2.1.2-py3.10-rocm6.1-ubuntu22.04
# Required environment variables
@@ -172,7 +172,7 @@ To request multiple GPUs, specify the quantity after the GPU name, separated by
# The name is optional, if not specified, generated randomly
name: axolotl-amd-llama31-train
- # Using RunPod's ROCm Docker image
+ # Using Runpod's ROCm Docker image
image: runpod/pytorch:2.1.2-py3.10-rocm6.0.2-ubuntu22.04
# Required environment variables
env:
diff --git a/src/dstack/_internal/core/backends/runpod/api_client.py b/src/dstack/_internal/core/backends/runpod/api_client.py
index 40b607aaf..a45a294ba 100644
--- a/src/dstack/_internal/core/backends/runpod/api_client.py
+++ b/src/dstack/_internal/core/backends/runpod/api_client.py
@@ -108,7 +108,7 @@ def edit_pod(
container_disk_in_gb: int,
container_registry_auth_id: str,
# Default pod volume is 20GB.
- # RunPod errors if it's not specified for podEditJob.
+ # Runpod errors if it's not specified for podEditJob.
volume_in_gb: int = 20,
) -> str:
resp = self._make_request(
@@ -320,7 +320,7 @@ def _make_request(self, data: Optional[Dict[str, Any]] = None) -> Response:
)
response.raise_for_status()
response_json = response.json()
- # RunPod returns 200 on client errors
+ # Runpod returns 200 on client errors
if "errors" in response_json:
raise RunpodApiClientError(errors=response_json["errors"])
return response
diff --git a/src/dstack/_internal/core/backends/runpod/compute.py b/src/dstack/_internal/core/backends/runpod/compute.py
index bd5ae0e8c..ec0336258 100644
--- a/src/dstack/_internal/core/backends/runpod/compute.py
+++ b/src/dstack/_internal/core/backends/runpod/compute.py
@@ -50,7 +50,7 @@
CONTAINER_REGISTRY_AUTH_CLEANUP_INTERVAL = 60 * 60 * 24 # 24 hour
-# RunPod does not seem to have any limits on the disk size.
+# Runpod does not seem to have any limits on the disk size.
CONFIGURABLE_DISK_SIZE = Range[Memory](min=Memory.parse("1GB"), max=None)
diff --git a/src/dstack/_internal/core/backends/runpod/models.py b/src/dstack/_internal/core/backends/runpod/models.py
index 076d67cfa..7bc11c281 100644
--- a/src/dstack/_internal/core/backends/runpod/models.py
+++ b/src/dstack/_internal/core/backends/runpod/models.py
@@ -20,7 +20,7 @@ class RunpodBackendConfig(CoreModel):
type: Literal["runpod"] = "runpod"
regions: Annotated[
Optional[List[str]],
- Field(description="The list of RunPod regions. Omit to use all regions"),
+ Field(description="The list of Runpod regions. Omit to use all regions"),
] = None
community_cloud: Annotated[
Optional[bool],
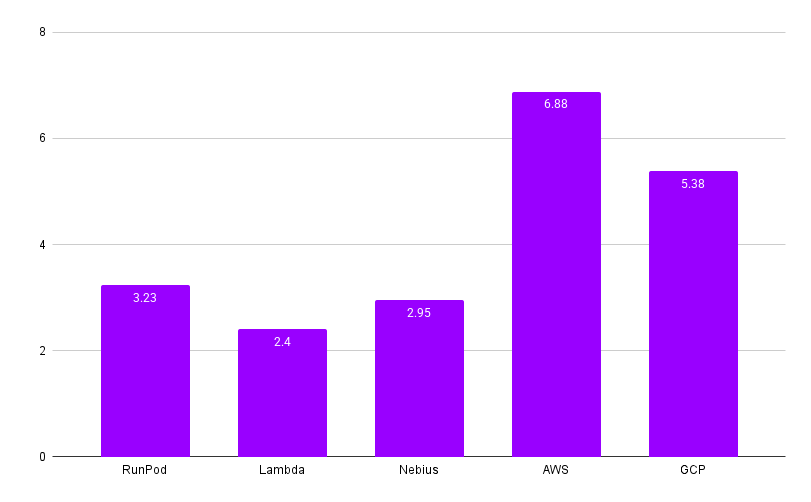 -> Most hyperscalers and neoclouds need short- or long-term contracts, though providers like RunPod, DataCrunch, and Nebius offer on-demand clusters. Larger capacity and longer commitments bring bigger discounts — Nebius offers up to 35% off for longer terms.
+> Most hyperscalers and neoclouds need short- or long-term contracts, though providers like Runpod, DataCrunch, and Nebius offer on-demand clusters. Larger capacity and longer commitments bring bigger discounts — Nebius offers up to 35% off for longer terms.
## New GPU generations – why they matter
diff --git a/docs/blog/posts/toffee.md b/docs/blog/posts/toffee.md
index 3854937e5..190ecf8c2 100644
--- a/docs/blog/posts/toffee.md
+++ b/docs/blog/posts/toffee.md
@@ -20,7 +20,7 @@ In a recent engineering [blog post](https://research.toffee.ai/blog/how-we-use-d
[Toffee](https://toffee.ai) builds AI-powered experiences backed by LLMs and image-generation models. To serve these workloads efficiently, they combine:
-- **GPU neoclouds** such as [RunPod](https://www.runpod.io/) and [Vast.ai](https://vast.ai/) for flexible, cost-efficient GPU capacity
+- **GPU neoclouds** such as [Runpod](https://www.runpod.io/) and [Vast.ai](https://vast.ai/) for flexible, cost-efficient GPU capacity
- **AWS** for core, non-AI services and backend infrastructure
- **dstack** as the orchestration layer that provisions GPU resources and exposes AI models via `dstack` [services](../../docs/concepts/services.md) and [gateways](../../docs/concepts/gateways.md)
@@ -68,7 +68,7 @@ Beyond oechestration, Toffee relies on `dstack`’s UI as a central observabilit
-> Most hyperscalers and neoclouds need short- or long-term contracts, though providers like RunPod, DataCrunch, and Nebius offer on-demand clusters. Larger capacity and longer commitments bring bigger discounts — Nebius offers up to 35% off for longer terms.
+> Most hyperscalers and neoclouds need short- or long-term contracts, though providers like Runpod, DataCrunch, and Nebius offer on-demand clusters. Larger capacity and longer commitments bring bigger discounts — Nebius offers up to 35% off for longer terms.
## New GPU generations – why they matter
diff --git a/docs/blog/posts/toffee.md b/docs/blog/posts/toffee.md
index 3854937e5..190ecf8c2 100644
--- a/docs/blog/posts/toffee.md
+++ b/docs/blog/posts/toffee.md
@@ -20,7 +20,7 @@ In a recent engineering [blog post](https://research.toffee.ai/blog/how-we-use-d
[Toffee](https://toffee.ai) builds AI-powered experiences backed by LLMs and image-generation models. To serve these workloads efficiently, they combine:
-- **GPU neoclouds** such as [RunPod](https://www.runpod.io/) and [Vast.ai](https://vast.ai/) for flexible, cost-efficient GPU capacity
+- **GPU neoclouds** such as [Runpod](https://www.runpod.io/) and [Vast.ai](https://vast.ai/) for flexible, cost-efficient GPU capacity
- **AWS** for core, non-AI services and backend infrastructure
- **dstack** as the orchestration layer that provisions GPU resources and exposes AI models via `dstack` [services](../../docs/concepts/services.md) and [gateways](../../docs/concepts/gateways.md)
@@ -68,7 +68,7 @@ Beyond oechestration, Toffee relies on `dstack`’s UI as a central observabilit
 -> *Thanks to dstack’s seamless integration with GPU neoclouds like RunPod and Vast.ai, we’ve been able to shift most workloads off hyperscalers — reducing our effective GPU spend by roughly 2–3× without changing a single line of model code.*
+> *Thanks to dstack’s seamless integration with GPU neoclouds like Runpod and Vast.ai, we’ve been able to shift most workloads off hyperscalers — reducing our effective GPU spend by roughly 2–3× without changing a single line of model code.*
>
> *— [Nikita Shupeyko](https://www.linkedin.com/in/nikita-shupeyko/), AI/ML & Cloud Infrastructure Architect at Toffee*
diff --git a/docs/blog/posts/volumes-on-runpod.md b/docs/blog/posts/volumes-on-runpod.md
index de0c8d6d0..c17faf7b1 100644
--- a/docs/blog/posts/volumes-on-runpod.md
+++ b/docs/blog/posts/volumes-on-runpod.md
@@ -1,24 +1,24 @@
---
-title: Using volumes to optimize cold starts on RunPod
+title: Using volumes to optimize cold starts on Runpod
date: 2024-08-13
-description: "Learn how to use volumes with dstack to optimize model inference cold start times on RunPod."
+description: "Learn how to use volumes with dstack to optimize model inference cold start times on Runpod."
slug: volumes-on-runpod
categories:
- Changelog
---
-# Using volumes to optimize cold starts on RunPod
+# Using volumes to optimize cold starts on Runpod
Deploying custom models in the cloud often faces the challenge of cold start times, including the time to provision a
new instance and download the model. This is especially relevant for services with autoscaling when new model replicas
need to be provisioned quickly.
Let's explore how `dstack` optimizes this process using volumes, with an example of
-deploying a model on RunPod.
+deploying a model on Runpod.
-Suppose you want to deploy Llama 3.1 on RunPod as a [service](../../docs/concepts/services.md):
+Suppose you want to deploy Llama 3.1 on Runpod as a [service](../../docs/concepts/services.md):
-> *Thanks to dstack’s seamless integration with GPU neoclouds like RunPod and Vast.ai, we’ve been able to shift most workloads off hyperscalers — reducing our effective GPU spend by roughly 2–3× without changing a single line of model code.*
+> *Thanks to dstack’s seamless integration with GPU neoclouds like Runpod and Vast.ai, we’ve been able to shift most workloads off hyperscalers — reducing our effective GPU spend by roughly 2–3× without changing a single line of model code.*
>
> *— [Nikita Shupeyko](https://www.linkedin.com/in/nikita-shupeyko/), AI/ML & Cloud Infrastructure Architect at Toffee*
diff --git a/docs/blog/posts/volumes-on-runpod.md b/docs/blog/posts/volumes-on-runpod.md
index de0c8d6d0..c17faf7b1 100644
--- a/docs/blog/posts/volumes-on-runpod.md
+++ b/docs/blog/posts/volumes-on-runpod.md
@@ -1,24 +1,24 @@
---
-title: Using volumes to optimize cold starts on RunPod
+title: Using volumes to optimize cold starts on Runpod
date: 2024-08-13
-description: "Learn how to use volumes with dstack to optimize model inference cold start times on RunPod."
+description: "Learn how to use volumes with dstack to optimize model inference cold start times on Runpod."
slug: volumes-on-runpod
categories:
- Changelog
---
-# Using volumes to optimize cold starts on RunPod
+# Using volumes to optimize cold starts on Runpod
Deploying custom models in the cloud often faces the challenge of cold start times, including the time to provision a
new instance and download the model. This is especially relevant for services with autoscaling when new model replicas
need to be provisioned quickly.
Let's explore how `dstack` optimizes this process using volumes, with an example of
-deploying a model on RunPod.
+deploying a model on Runpod.
-Suppose you want to deploy Llama 3.1 on RunPod as a [service](../../docs/concepts/services.md):
+Suppose you want to deploy Llama 3.1 on Runpod as a [service](../../docs/concepts/services.md):