Table of Contents generated with DocToc
- 深入学习 Node.js Module
- Node.js 中的循环依赖
- 浅析 NodeJs 的几种文件路径
- Node.js module.exports vs. exports
- module.exports vs exports in Node.js
require vs import
-
CommonJS 模块输出的是一个值的拷贝,ES6 模块输出的是值的引用
-
CommonJS 模块是运行时加载,ES6 模块是编译时加载输出接口
export vs export default
- 浅析 Node 进程与线程
- NodeJS 充分利用多核 CPU 以及它的稳定性
- 当我们谈论 cluster 时我们在谈论什么
- NodeJS 多进程
- Node.js 软肋之 CPU 密集型任务
- [转] Node.js 的线程和进程详解
事件循环/任务调度
- The JavaScript Event Loop: Explained
- Concurrency model and the event loop
- 【译】【Node.js at Scale】理解 Node.js 中的事件循环
- Tasks, microtasks, queues and schedules
- 微任务、宏任务与 Event-Loop
- async await 和 promise 微任务执行顺序问题
setTimeout 问题
- Difference between setTimeout(fn, 0) and setTimeout(fn, 1)?
- Why is setTimeout(fn, 0) sometimes useful?
/*
* 宏任务:
* 1. I/O
* 2. setTimeout/setInterval/setImmediate
* 3. requestAnimationFrame
*
* 微任务:
* 1. process.nextTick
* 2. Promise.then/.catch/.finally
*/
// 注意,new Promise 在实例化的过程中所执行的代码都是同步进行的,而 then 中注册的回调才是异步执行的
// async 函数在 await 之前的代码都是同步执行的,可以理解为 await 之前的代码属于 new Promise 时传入的代码,await 之后的所有代码都是在 Promise.then 中的回调setTimeout(() => {
console.log(1)
}, 0)
new Promise((resolve) => {
console.log(2)
for (let i = 0; i < 100; i += 1) {
if (i === 88) resolve()
}
console.log(3)
}).then(() => {
console.log(4)
})
console.log(5)
// 2 3 5 4 1- Speeding up spread elements
- Fast async
- V8 引擎的垃圾回收策略
- 【译】【Node.js at Scale】Node.js 的垃圾回收机制
- 4 类 JavaScript 内存泄漏及如何避免
数据类型,原型/原型链
- 细说 JavaScript 七种数据类型
- 判断 JS 数据类型的四种方法
- JavaScript 中的四舍五入
- 认识原型对象和原型链
- 函数作用域和作用域链
- 你不知道的 JavaScript
- JavaScript 浮点数陷阱及解法
- 不要再问我 this 的指向问题了
原型/原型链
JS 中可分为普通对象Object和函数对象Function。通过new Function产生的对象、声明的函数是函数对象,其他对象都是普通对象
prototype即原型对象,它记录着对象的一些属性和方法。
prototype对于父对象本身是不可见的,但子类可以完全访问。当通过new操作符创建新对象的时候,通常会把父类的prototype赋值给新对象的__proto__属性,子类就可以调用到继承的属性或方法。
原型链的形成真正是靠__proto__而非prototype,当 JS 引擎执行对象的方法时,先查找对象本身是否存在该方法,如果不存在,会在原型链上查找,但不会查找自身的prototype
function func() {}
func.prototype.foo = 'foo'
console.log(func.foo) // undefined
const f = new func()
console.log(f.foo) // foo向上追溯原型链:
f.__proto__->func.prototypefunc.prototype.__proto__->Object.prototypeObject.prototype.__proto__->null
提升
// 函数声明会被提升
console.log(a) // ƒ a() { console.log('1') }
a() // 1
function a() { console.log('1') }
var a = function() { console.log('2' )}
console.log(a) // ƒ () { console.log('2' )}// 但函数表达式不会被提升
console.log(a) // undefined
a() // TypeError
var a = function() { console.log('2' )}
console.log(a) // ƒ () { console.log('2' )}var a = function() { this.b = 1 }
a.prototype.b = 9
var c = new a()
var b = 2
a()
console.log(b)
console.log(c.b)Map/WeakMap, Set/WeakSet
判断操作
- How JavaScript works: An overview of the engine, the runtime, and the call stack
- How JavaScript works: Inside the V8 engine + 5 tips on how to write optimized code
- How JavaScript works: Memory management + how to handle 4 common memory leaks
- How JavaScript works: Event loop and the rise of Async programming + 5 ways to better coding with async/await
- How JavaScript works: Storage engines + how to choose the proper storage API
/*
* Some fact:
* 1. 调用 resolve 或 reject 并不会终结 Promise 的参数函数的执行
* 2. Promise 在 resolve 语句后面,再抛出错误,不会被捕获,等于没有抛出。因为 Promise 的状态一旦改变,就永久保持该状态,不会再变了
* 3. new Promise 在实例化的过程中所执行的代码都是同步进行的,而 then 中注册的回调才是异步执行的
* 4. async functions always return promises
*/- 前端高性能动画最佳实践
- 前端工程与性能优化
- Cookie/Session
- 事件冒泡 和 事件捕获
- 跨域问题
-
deepcopy 实现
-
Immutable.js
JSON.parse(JSON.stringify(obj)) // hack
// Issues with Date() when using JSON.stringify() and JSON.parse()
// https://stackoverflow.com/questions/11491938/issues-with-date-when-using-json-stringify-and-json-parse/- 防抖
debounce: 事件被触发后 N 秒内不能重复执行。如果执行,则 N 重新计时 - 节流
throttle: 如果持续触发一个事件,则在一定的时间内只执行一次事件
- Future JavaScript: what is still missing?
- ECMAScript 2019: the final feature set
- What's New in ES2019: Array flat and flatMap, Object.fromEntries
- New ES2018 Features Every JavaScript Developer Should Know
- Functional-Light JavaScript
- For vs forEach() vs for/in vs for/of in JavaScript
http 数据分隔 CLRF(\r\n)
TCP/UDP/IP
- TCP/IP 协议知识科普
- 深入浅出 TCP/IP 协议栈
- 面试官,不要再问我三次握手和四次挥手
- 通俗大白话来理解 TCP 协议的三次握手和四次分手
- TCP 的那些事儿(上)
- Mac 地址会不会有重复的?怎么做到全球唯一的?如果网卡作废了,那么 Mac 地址回收吗?
- TCP/IP、Http、Socket 的区别
- 如何通俗地解释一下 TCP/UDP 协议和 HTTP、FTP、SMTP 等协议之间的区别?
- TCP 为什么需要第三次握手?第三次握手失败了会怎么样?
- TCP 流量控制中的滑动窗口大小、TCP 字段中16位窗口大小、MTU、MSS、缓存区大小有什么关系?
调优
TCP 连接和挥手过程:
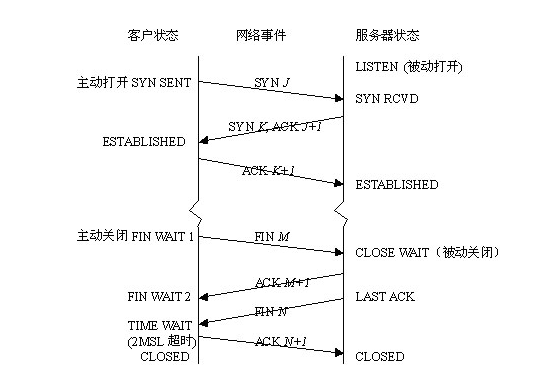
TIME_WAIT是主动关闭方在收到被动关闭方发的FIN包之后处于的状态, 这个包是主动关闭方收到的最后一个包了, 在收到这个包之后还不能直接就把连接给关闭了, 还得等待一段时间才能关闭, 等待时间为2MSL。
为什么要等待一段时间呢? 主要是两个原因:
- 在收到最后一个包之后主动关闭方还得发一个
ACK回去, 这个ACK可能会丢包, 如果丢包, 对方还需要重新发最后一个FIN包, 如果收到重新发过来的FIN包的时候这边连接已经关闭, 则会导致连接异常终止; - 不过第 1 点也不会造成太大的问题, 毕竟数据已经正常交互了。但是有另外一点风险更高, 就是如果不等待
2MSL的话, 那么如果正好一个新连接又建立在相同的端口上, 那么上次的FIN包可能因为网络原因而延时的包,这个时候才送达该端口, 导致下一次连接出现问题;
所以一定要有一个TIME_WAIT的状态等待一段时间, 等待的MSL时间RFC上面建议是 2 分钟
但是如果你的服务是一个高并发短连接服务, TIME_WAIT可能会导致连接句柄被大量占用, 而你又相信服务内部是一个非常稳定的网络服务, 或者即使有两个连接交互出现故障也可以接受或者有应用层处理, 不希望有那么多的TIME_WAIT状态的连接, 一般有两种方式:
- 在建立连接的时候使用
SO_REUSEADDR选项 - 在
/etc/sysctl.conf中加入如下内容:
# 表示开启 TCP 连接中 TIME-WAIT sockets 的快速回收,默认为 0,表示关闭
net.ipv4.tcp_tw_recycle = 1
# 表示开启重用。允许将 TIME-WAIT sockets 重新用于新的 TCP 连接,默认为 0,表示关闭
net.ipv4.tcp_tw_reuse = 1
# 对于本端断开的 socket 连接,TCP 保持在 FIN-WAIT-2 状态的时间。对方可能会断开连接或一直不结束连接或不可预料的进程死亡。默认值为 60 秒
# 即 MSL。断开连接四次挥手时,最后会等待 2MSL 后释放文件句柄
net.ipv4.tcp_fin_timeout = 1
# 在每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目
net.core.netdev_max_backlog = 4000然后执行/sbin/sysctl -p生效参数
- 高性能网络编程(一):单台服务器并发 TCP 连接数到底可以有多少
- 高性能网络编程(二):上一个10年,著名的 C10K 并发连接问题
- 高性能网络编程(三):下一个 10 年,是时候考虑 C10M 并发问题了
- 高性能网络编程(四):从 C10K 到 C10M 高性能网络应用的理论探索
- 高性能网络编程(五):一文读懂高性能网络编程中的 I/O 模型
- 高性能网络编程(六):一文读懂高性能网络编程中的线程模型
- 高性能网络编程经典:《The C10K problem(英文)》[附件下载]
连接基本过程:
- 客户端请求服务端,服务端给出自己证书
- 浏览器从证书中拿出服务端公钥 A
- 浏览器生成自己的对称密钥 B,用公钥 A 加密 B 后传输给服务端
- 服务端用私钥 C 解密,获取到对称密钥 B
- 之后两端通讯使用对称密钥 B 加密
证书合法性检查:
- 首先,证书中包含:签发机构 CA、数字签名(用 CA 私钥加密摘要)、证书持有者公钥 A、签名的 hash 算法
- 数字签名的由来:明文 -> hash 运算 -> 摘要 -> CA 私钥加密 -> 数字签名
- 其次,浏览器内置了 CA 的根证书,包含 CA 的公钥
- 浏览器收到服务端证书以后:
- 检查证书颁发机构是否存在,然后找到 CA 证书、CA 公钥
- 用 CA 公钥解密数字签名,解出被加密的证书摘要 AA
- 用证书中提供的 hash 算法,计算出当前证书的摘要 BB
- 比较 AA 和 BB
- 以上有任意一步失败,则会认为证书被伪造
React 虚拟 DOM
class Test {
constructor() {
this.echo = () => {
console.log('echo in constructor')
}
}
echo() {
console.log('echo')
}
}
Test.echo // error
new Test().echo() // echo in constructor