{kind=link}
{kind=link}
Natural Language Processing on our 16th President
Abraham Lincoln is arguably one of the most quoted authors in American History, and yet there has yet to be comprehensive NLP analysis performed on his writing. This project seeks to fill this gap. By getting a deeper understanding of Lincoln's writing, we can not only gain greater insights into some of his most famous works (How does his tone and subjectivity change throughout the Gettysburg Address?), but we can use patterns in his writing to gain greater insight into historical events and see how his writing changed in response to those events (What battles had the most outsized impact on his overall sentiment?).
The data for this project was mined from the University of Michigan. After building a script that could successfully retrieve all 6700 documents from Lincoln's Collected Writings, I created an EC2 instance in AWS and let the program run in that instance overnight. Once the data was pulled into that virtual machine, it was sent to an Amazon RDS PostgreSQL database where it is currently being housed.
To this point, I've primarily been cleaning the data and going through some exploratory work (Cleaning and EDA Script). The challenges of cleaning have been numerous. Chief among them is the fact that none of the documents are tagged with dates or information about their content. To combat this, I used regex to filter out the dates. This only gets us halfway home, unfortunately. There isn't currently a straightforward way for python data packages to handle dates before 1900. In light of that, I was forced to create a custom key based on how many months into the nineteenth century a document was written. There is more datetime cleaning that needs to be done, but being able to sort the data by month allows us to investigate the data more purposefully.
One of my initial goals in this project was to track Lincoln's sentiment throughout his presidency. Using TextBlob's sentiment analysis tools, I was able to create the following visualization. It shows Lincoln's monthly average sentiment during his presidency. I was surprised to see what a clear trend there was in this data.
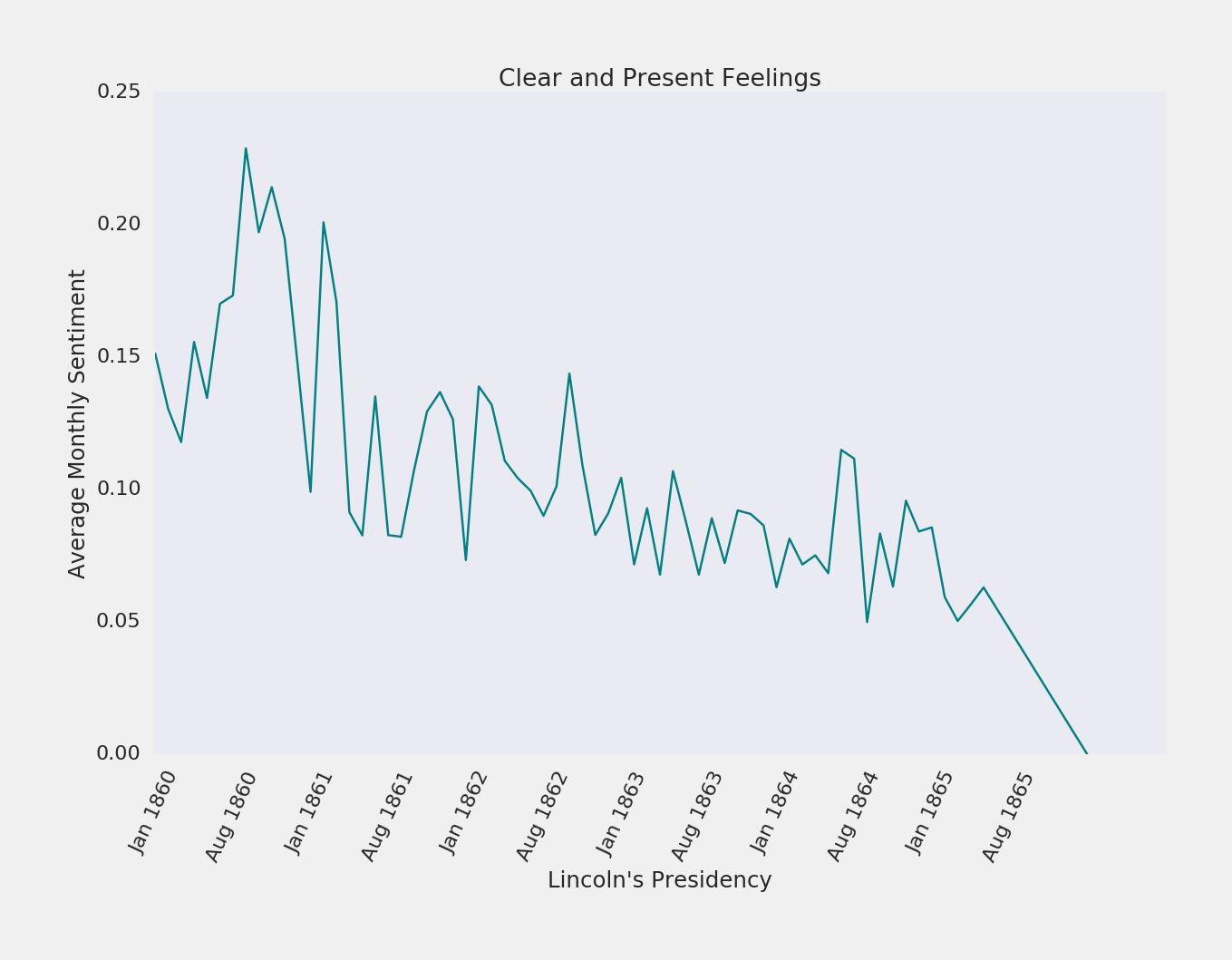
There are a lot of different avenues of this project that I would like to explore. Next, I intend to perform some topic modeling to see how well these texts could be broken up into different clusters. In order to do that, I'll combine some of the tools that SpaCy provides with some of the modules in the sk-learn library. Given the results of that topic modeling, I may investigate creating a "Lincoln Language Generator" that can take in any piece of text and translate it into "Lincolnese."
It bears emphasizing that this project has several modern, practical applications. The art of political rhetoric is a diffficult one to master, and there are few people who perfected that art better than Lincoln did. It's my hope that understanding what elements of his writings contribute to his rhetorical skill. The lessons learned in that work can easily be applied to modern rhetoric and provide a baseline for comparison. Also, the work of tracking sentiment over time is valuable across disciplines. Whether it's examining how different demographics respond to different topics, or tracking the change in a group's thinking over time, the lessons learned by tracking sentiment across Lincoln's work are readily applicable.